别再手抄文案了!
在上一期文章《A24 – 语音识别》中,我们科普了当下的语音识别技术,Whisper 是这个领域的“游戏改变者”。
而今天我们将迎来升级版本《语音一键识别》。
是真正的一键生成,
而且还是“手把手喂饭”的那种教程。
01
项目说明
在上一篇文章《A24 – 语音识别》中。
奶酪介绍了软件两款语音识别软件:WhisperDesktop 和 Buzz,它们都很好用,为什么又要开一个新的项目呢?
因为它们是图形化软件。
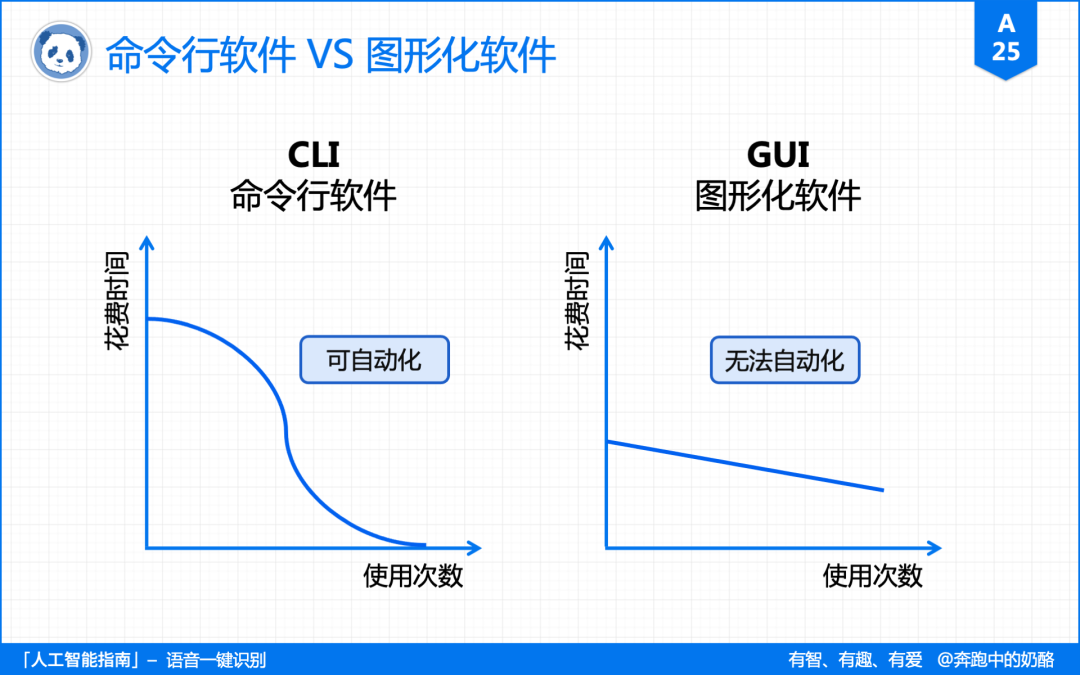
1.1、命令行软件
图形化软件的特点,是「所见即所得」。
它将所有的内容都放在眼前,我们只需要用鼠标点几下,即可完成任务,上手难度简单。
而命令行软件的特点,是「所想即所得」。
它可以将「逻辑文本化」,通过不同命令的组合,就可以实现任务的自动化,一键操作,还有无限复杂度的操作。
不过命令行软件的上手难度高,
可一旦你掌握后,你在这上面花费的时间,将无限趋近于零。
而且,命令行软件不但灵活方便,还可以跨平台使用,也就是说,本文适用了 Windows、Mac、Linux 三个平台。
1.2、安装 Python
而要使用 Whisper,我们还需要一些前置安装,这其中就包括 Python 和 FFmpeg。
目前 Whisper 只支持 Python 3.7 ~ 3.10 版本,暂不兼容 3.11,推荐使用 3.10.10 版本,还有 Win7 只支持 3.8。
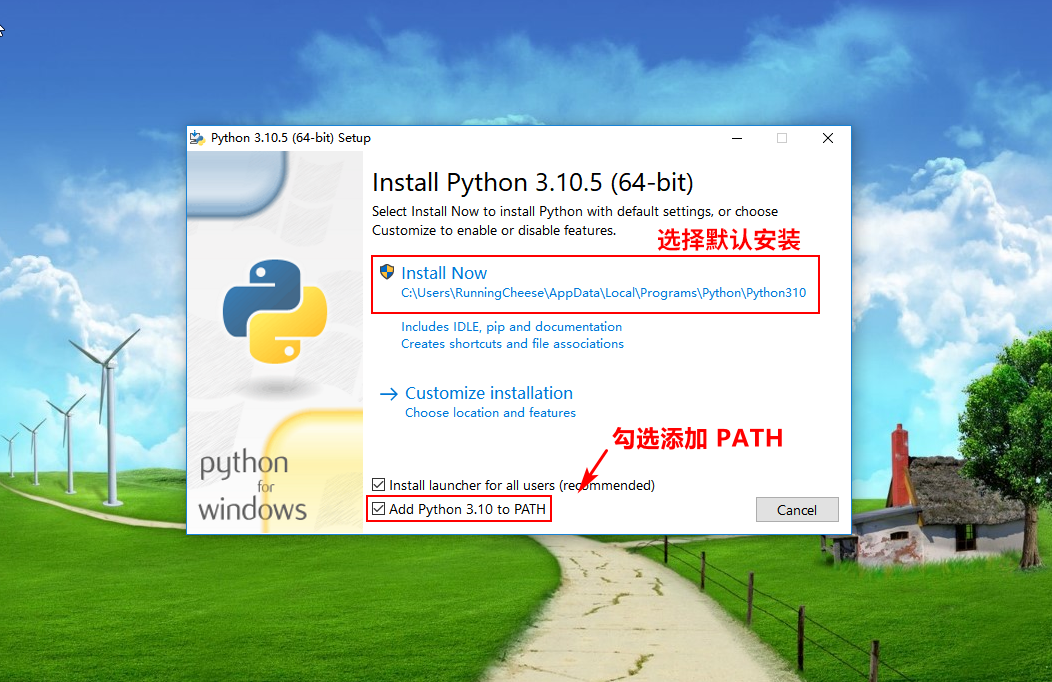
安装方法很简单,选择默认安装 ,并一路“确认”到底就可以了。
记得要勾选 Add Python 3.XX to PATH。
下载地址:
Windows 64位:https://www.python.org/ftp/python/3.10.10/python-3.10.10-amd64.exeWindows 32位:https://www.python.org/ftp/python/3.10.10/python-3.10.10.exeWin7 64位:https://www.python.org/ftp/python/3.8.8/python-3.8.8-amd64.exeWin7 32位:https://www.python.org/ftp/python/3.8.8/python-3.8.8.exeMac:https://www.python.org/ftp/python/3.10.10/python-3.10.10-macos11.pkg
1.3、安装 FFmpeg
同样,Whisper 还需要使用 FFmpeg 来提取声音数据,使用时不需要打开,它会自动调用。
下载地址:
Windows: https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-essentials.zip Mac: https://evermeet.cx/ffmpeg/ffmpeg-6.0.zip
如果遇到下载问题,或者你还可以回复关键字 A25 下载,奶酪已经把它们打包好了,你可以一键下载。
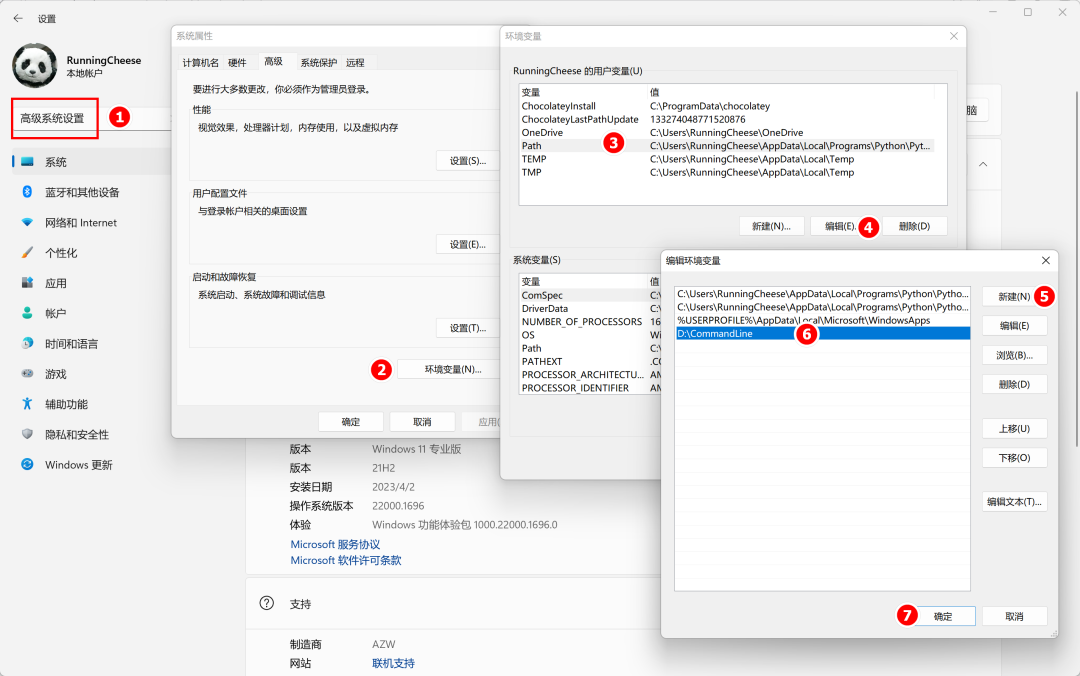
1.4、添加环境变量
下载 FFmpeg 后,我们不需要进行安装,而是要添加环境变量。
其目的,是为了在 CMD 窗口操作时,可以省去输入软件的具体路径,几乎所有的命令行工具都可以这样配置。
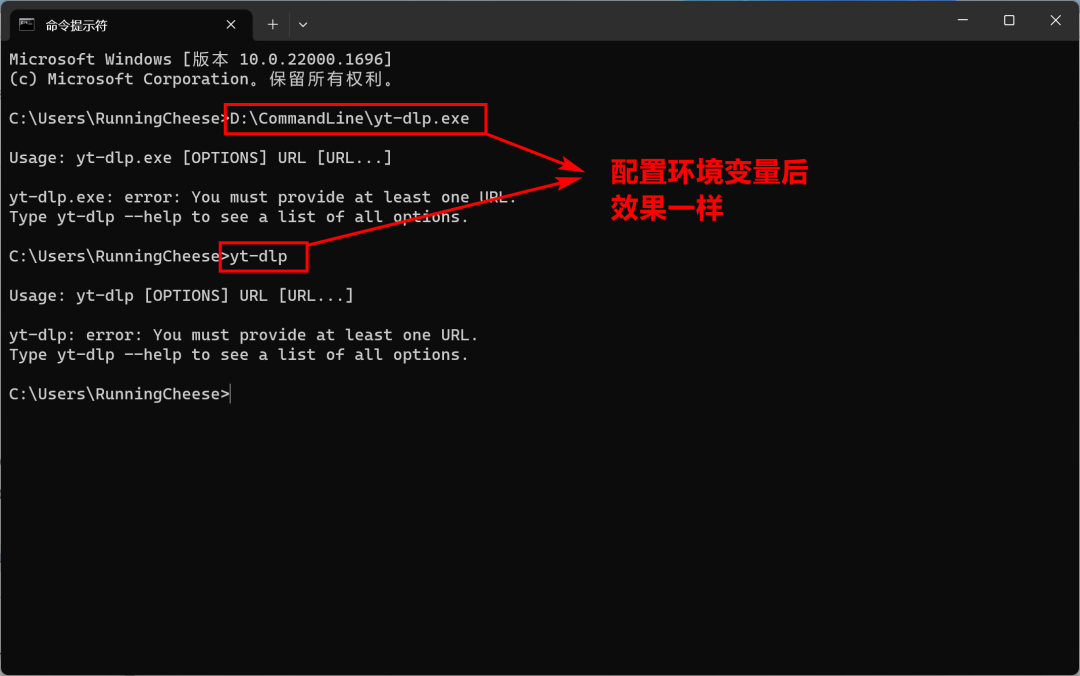
正因为如此。
我们可以将所有的命令行工具,都放在同一个文件夹下,只需要设置一次环境变量,那么所有软件就都会生效。
比如奶酪就将所有命令行软件放在 D:\Commandline 里。
添加环境变量的具体操作如下:
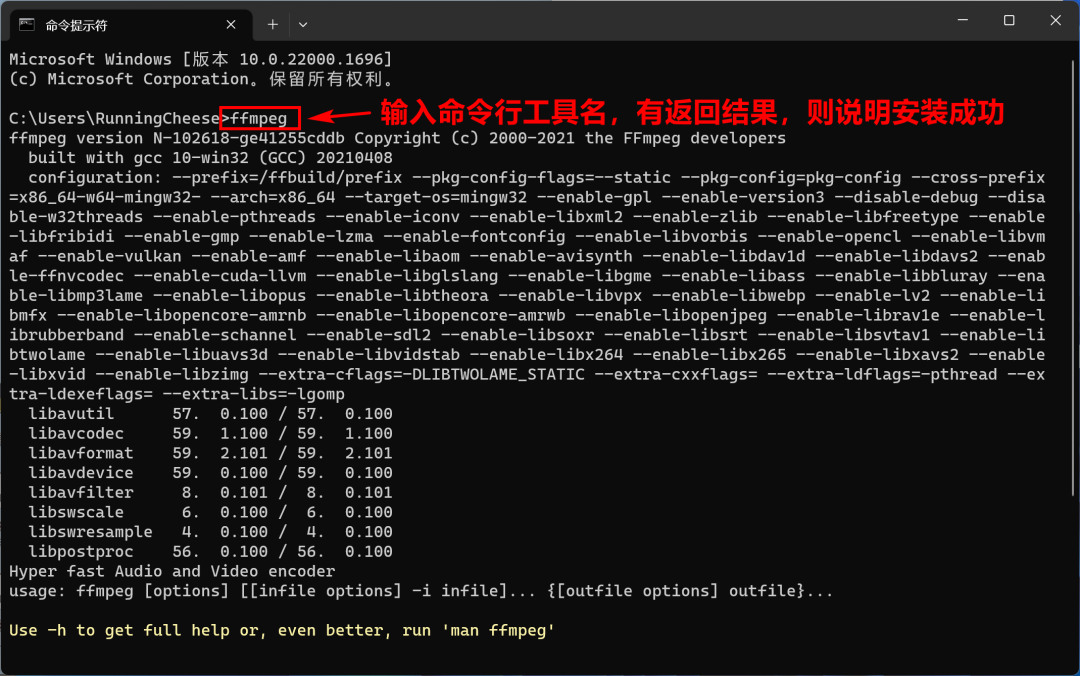
最后,如果在 CMD 窗口或终端输入 ffmpeg,有返回内容,则说明安装成功。
02
安装框架
安装好 Python 和 FFmpeg 后,要使用 Whisper,我们还需要安装 Python 框架,这里特别说明一下什么是框架。
2.1、框架是什么?
框架(Framework),通常是指某个领域里的通用解决方案。
用在编程开发领域的话,框架可以让提高开发效率,避免重复造轮子的问题,还可以让代码更易于维护和更新。
就好比“做菜“的框架,世界上就主要分成为了三大菜系:中国菜系、法国菜系和土耳其菜系。
2.2、深度学习框架
而在人工智能领域,深度学习的框架主要包括:TensorFlow、PyTorch、和 JAX。
TensorFlow 是谷歌推出的深度学习框架。
PyTorch 则是由脸书推出,如今已经成为了这个领域的霸主,OpenAI 的 Whisper 使用的正是这个框架。
JAX 则是谷歌为了应对 PyTorch 挑战而推出的 TensorFlow 简化版。
有网友将 Whisper 的框架换成 JAX 后,转换速度就比原版 Whisper 快了近 70 倍。

2.3、Whisper 框架
不过,考虑到 JAX 框架还不成熟,而且在 Windows 上无法原生运行,上手难度也大,对普通用户不友好。
所以,奶酪更推荐 Ctranslate2,它是 Transformer 系列模型的快速推理引擎。
而 Whisper-CTranslate2,可以说是目前最好的 Whisper 第三方实现。
地址:
https://github.com/Softcatala/whisper-ctranslate2
选择 Whisper-CTranslate2 的原因。
一是它在 CTranslate2 的加持下,速度比原版 Whisper 快了 4 倍。
二是它与原版 Whisper 命令兼容,可以省去学习成本。
三是它融合了众多 Whisper 第三方实现的优点,还解决了静默片段也识别为语音的 VAD 功能,转录更加准确。
03
Whisper-CT2
可以说,Whisper-CTranslate2 之于 Whisper,就像 yt-dlp 之于 youtube-dl。
下面我们详细说一下使用方法。
3.1、下载安装
只需要在 CMD 窗口或者终端输入以下命令即可完成安装。
安装:pip install whisper-ctranslate2 升级:pip install whisper-ctranslate2 –upgrade 卸载:pip uninstall whisper-ctranslate2 注意:如果是 MacOS 的话,需要将 pip 改为 pip3
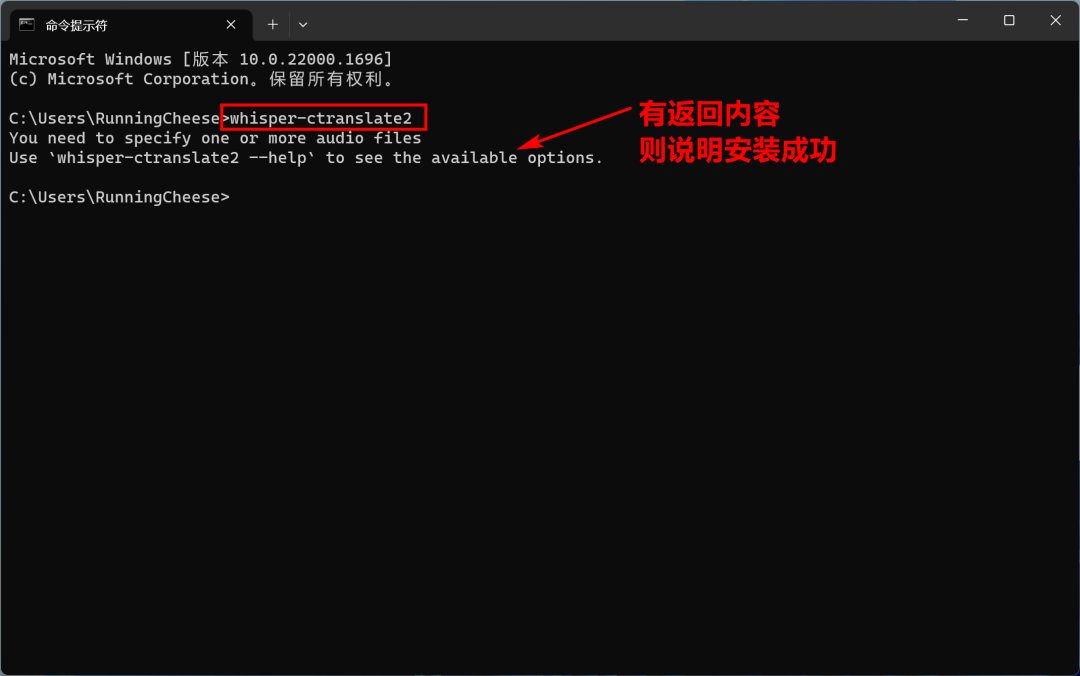
安装完成后,在CMD 窗口或者终端再次输入”whisper-ctranslate2” ,如果有返回内容,则说明安装成功。
3.2、命令参数
Whisper-CTranslate2 兼容原版 Whisper 命令,只需要运行 whisper-ctranslate2 audio.mp3 即可进行转录。
而要进行自定义设置,则可以在后面追加命令参数。
whisper-ctranslate2 audio.mp3 –命令参数
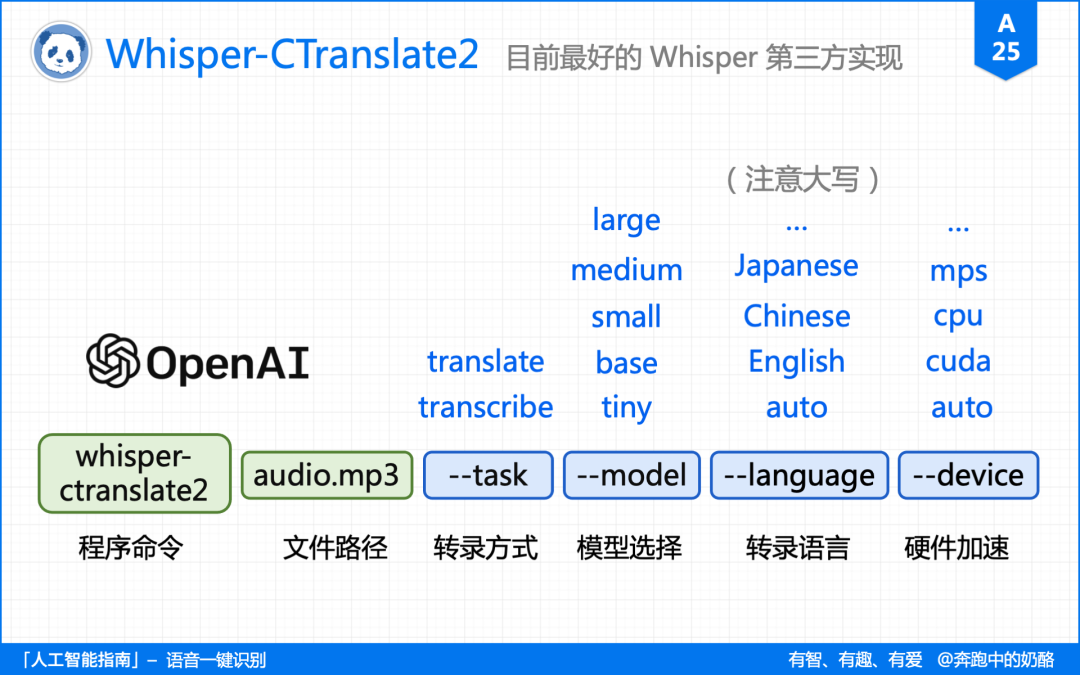
–task
指定转录方式,默认使用 –task transcribe 转录模式,–task translate 则为翻译模式,目前只支持英文。
–model
指定使用模型,默认使用 –model small,Whisper 还有英文专用模型,就是在名称后加上 .en,这样速度更快。
–language
指定转录语言,默认会截取 30 秒来判断语种,但最好指定为某种语言,比如指定中文是 –language Chinese。
–device
指定硬件加速,默认使用 auto 自动选择, –device cuda 则为显卡,cpu 就是 CPU, mps 为苹果 M1 芯片。
–vad_filter
这是 Whiper-CTranslate2 特有的命令,设置 –vad_filter True 后,能解决“幻听”,还有字幕不对轨的问题。
–live_transcribe
这个也是特有的命令,设置 –live_transcribe True –language Chinese 后,即可用麦克风进行实时转录。
–help
查看 Whiper-CTranslate2 所有的命令,输入 whisper-ctranslate2 -h 或者 –help 即可查看。
3.3、使用方法
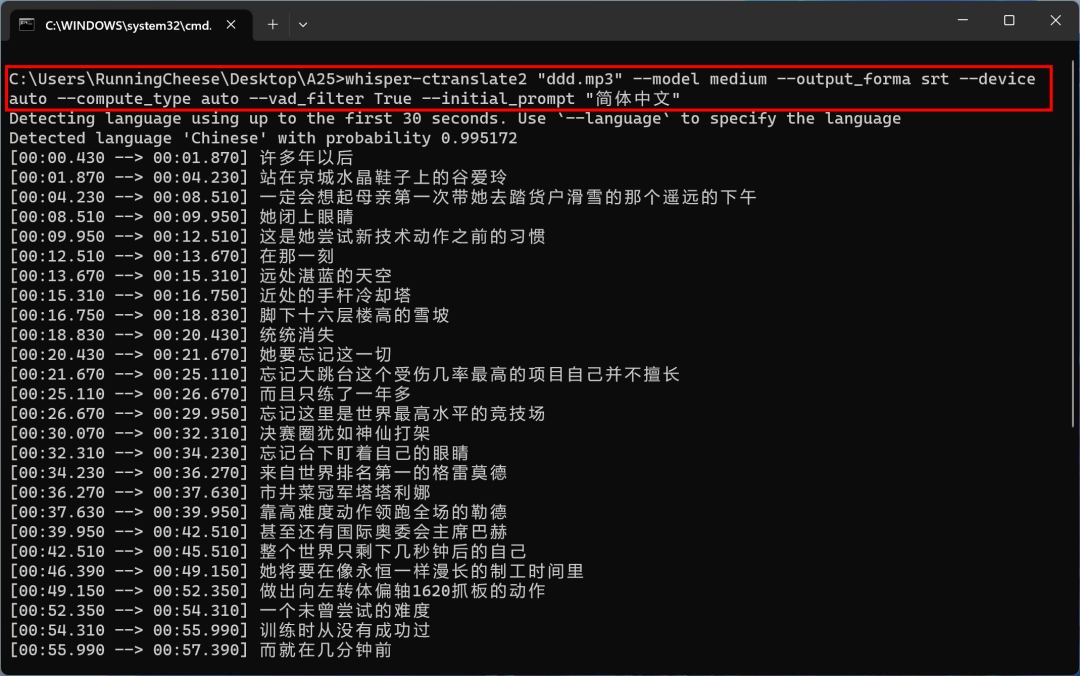
组合你需要的命令参数,在 CMD 窗口或终端输入即可进行转录,如果第一次使用,则会先下载 Whisper 模型。
模型的具体保存位置在:
Mac:~/.cache/huggingface Windows:C:\Users\<你的用户名>\.cache\huggingface
04
语音一键识别
当然,教程到这里还远谈不上“语音一键识别”,前面都只是铺垫,接下来就是本文的“爽点”内容了。
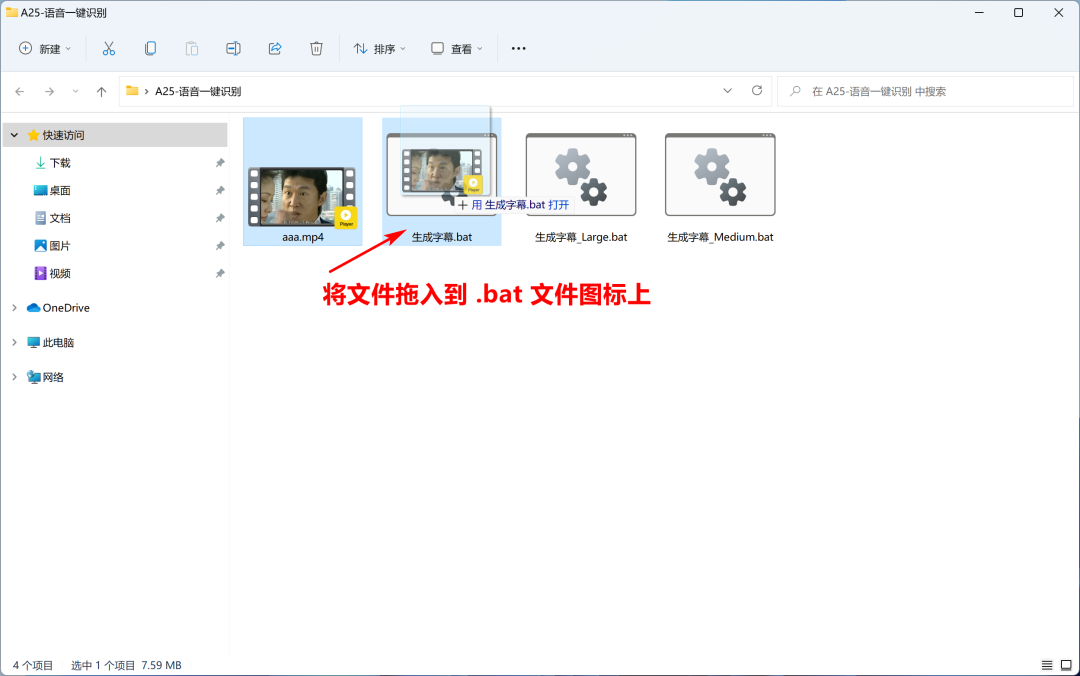
4.1、一键生成字幕
我们可以将常用的 Whisper 命令,用 bat 批处理文件保存起来,然后将音/视频文件拖入到 bat 文件上一键转录。
默认使用 small 模型,速度更快,想要更准确的话,可以选择使用 medium 模型。
如果你有高性能独立显卡的话,还可以选择 large 模型。
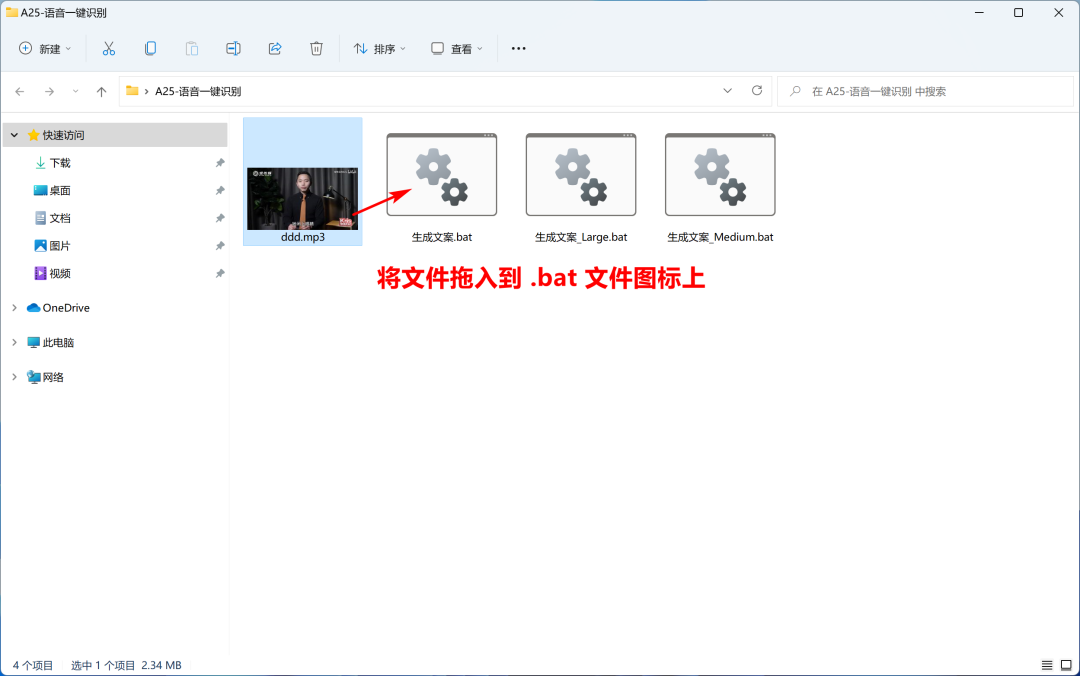
4.2、一键生成文案
如果你不是想生成字幕,而是想把视频里的台词文案导出为 txt 文件,则可以选择用这个 .bat 文件。
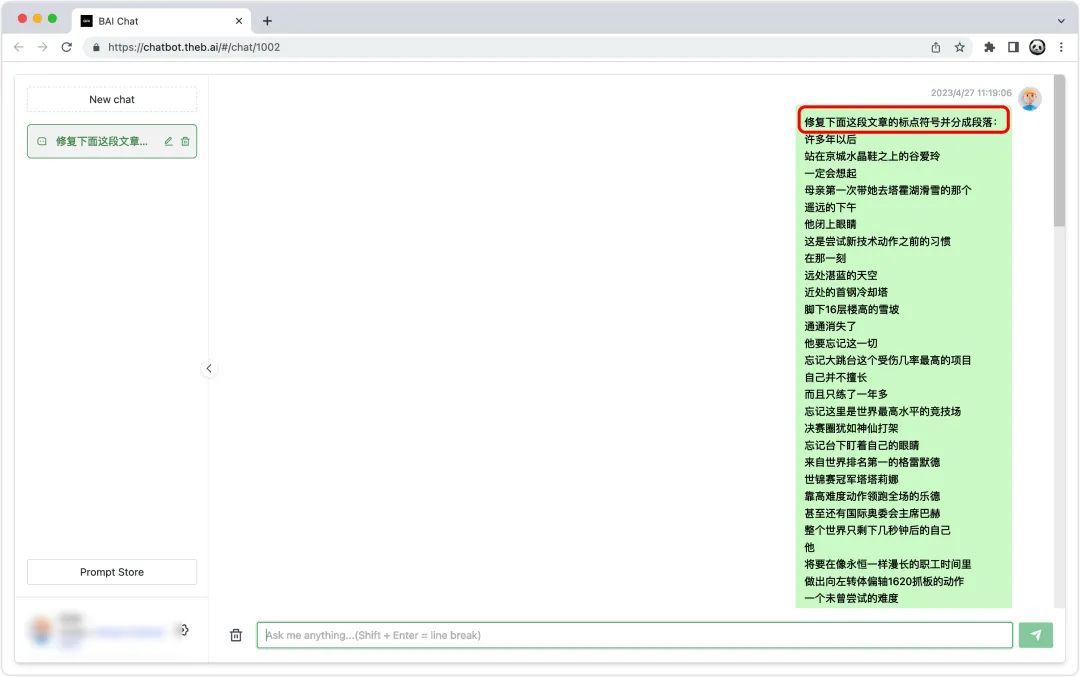
导出的文档默认没有标点符号和排版。
一个简单的解决方法,是利用 ChatGPT 来重新排版,只需要提前输入提示词就可以了,具体是:
修复下面这段文章的标点符号并分成段落:<文本内容>
需要注意的是,GPT-3.5 输出的最大限制是 777 个字符,所以每一次输入最好不要超过 777 个中文。
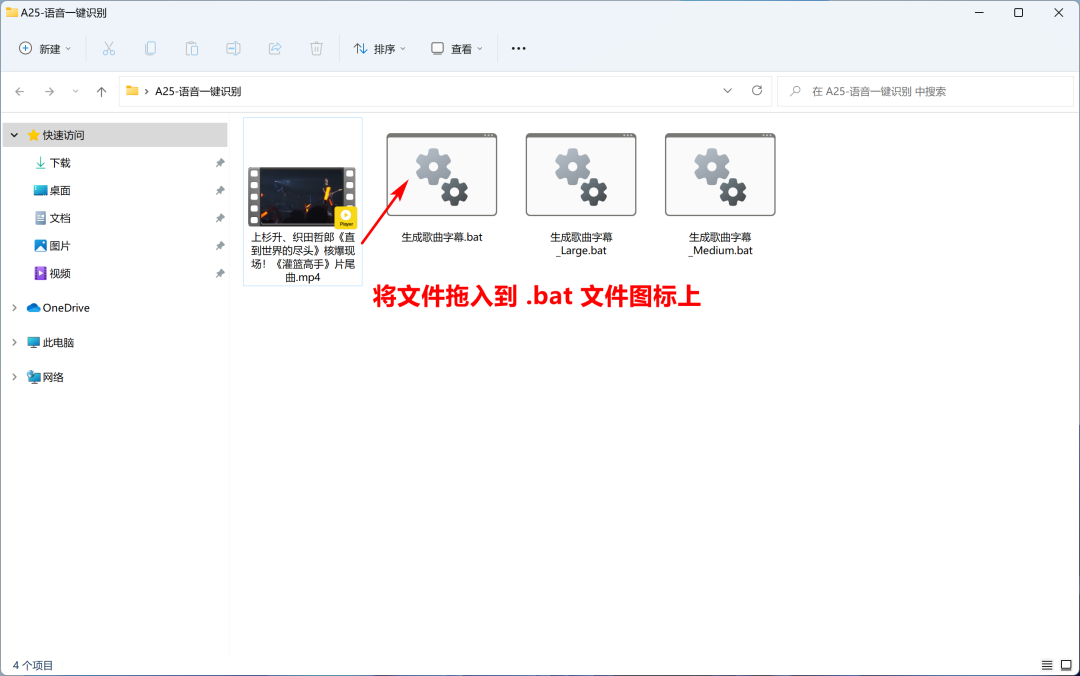
4.3、一键歌曲字幕
上面的 bat 文件,默认都启用了 –vad_filter 参数,它可以解决转录“幻听”的问题,但它不适用于歌曲转录。
它会导致歌词被忽略,所以可以用下面这个单独的 .bat 文件。
最后,你可以在公众号后台回复关键字 A25,获取以上奶酪制作的 .bat 文件。
05
BT 下载的思路
说了这么多,你可能会说”这也太复杂了吧“?
说得系统全面,是奶酪的文章风格,因为追求“原创新鲜、系统连贯、给渔授渔”,而实际的操作,其实就 5 步。
1、安装 Python 和 FFmpeg,并添加环境变量。
2、安装 Whisper-CTranslate2。
3、下载奶酪的 .bat 文件。
4、将需要转录的文件,拖到 bat 文件图标上。
5、等待转录完成。
而配置好后,其实你只需要“将文件拖入 bat 文件图标”这 1 个步骤。
甚是美哉!
结尾
许多年以后,
打开电脑看视频时的奶酪,一定会想年轻时自己在屏幕面前手敲字幕敲到手抽筋的那个下午。
而现在,我总结了目前最快的语音识别的方法了。
而且也没有比这更快的了!
















评论前必须登录!
立即登录 注册